Winapp fuzzing: Winnie/harnessgen
emo 了好长一段时间,因为焦虑无法集中注意力,做什么事也都提不起来兴趣。比赛好长时间没打了,没有学到什么东西,博客也断更了几个月。希望能通过再写写博客的方式,提升一点学习的专注度。;(
Introduction
Winnie-AFL 是 gatech 在 “Windows 应用层 Fuzzing” 上的一个研究成果,发表在 NDSS 2021 上(paper 传送门)。主要有两个方面的贡献:
- 基于调用跟踪自动生成 harness 的方法,这部分论文里面方法讲得比较详细
- 实现 Windows 平台的 fork(),这部分 repo 里面介绍得比较详细
两部分的工作相对正交,本文只关注前半部分 harnessgen
Methodology
看完源码发现实现中有些出入,注释到了对应的地方
首先 Winnie 会关注于文件操作,从调用跟踪中识别合适的模糊测试目标函数;然后恢复调用的序列和确定一些参数的性质;然后处理控制流和数据流的一些依赖问题;最后对生成的 harness 有一个初步的测试筛选。
Fuzzing Target Identification
首先需要手动运行目标获得 Trace(Winnie 的一个 motivation 是认为基于 GUI 的程序直接测试很慢,但如果只手动运行几次然后根据 Trace 生成不涉及 GUI 的 harness 就会快很多,当然这个方法本身的局限就是无法测试到 Trace 中没有暴露的函数)
- 记录所有的模块名称和基地址。
- 记录模块之间的调用和跳转信息,并记录下线程 ID(Winnie 的分析只基于单个线程)。记录下 CPU 和堆栈作为潜在参数,并当数值落入可访问内存时递归地进行解引用,还识别常见的字符串编码(可以用来匹配样本文件名)。
- 在遇到返回指令时记录下返回值。
文中认为好的模糊测试目标 API 应该是以下情形之一(是否有实验数据作为支撑?):
- 库接受用户提供的文件路径作为输入,打开文件,解析内容并且关闭文件
- 接受文件描述符或内存缓冲区(Winnie 会检查内存缓冲区是否包含文件内容)作为输入
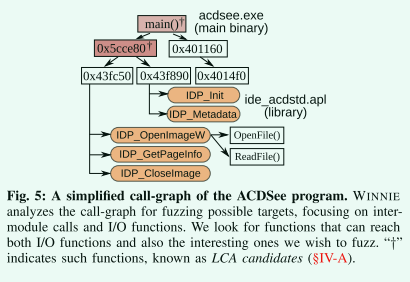
Winnie 选择从 I/O 函数和上一步之前确定的解析库 API 的最低共同祖先 (LCA),并将目标祖先也作为备选目标。
实际上并没有检查文件描述符和内存缓冲区,只是将 CreateFile 到 ClodeFile 之间的所有函数调用作为目标进行了 LCA分析。
Call-sequence Recovery
我们搜索与该库相关的函数调用的轨迹,并将它们复制到harness骨架。
Winnie 还使用 IDA 和 Ghidra 提供的静态分析来推断函数的原型(IDA 的分析可能比较有局限性)。
实际上只使用了 IDA 提供的函数原型数据
Argument Recovery
Winnie 尝试将跟踪中记录的原始参数值符号化为变量和常量:
-
确定指针参数:通过差异分析(基于 ASLR)来判断,跟踪具体的内存内容,分解多级指针。
实际上并没有做差异分析,能够指向有效地址的被判定为是指针
-
确定参数是常量还是变量:跟踪中具有变化的值是变量,具有恒定的值是常量。
差异分析也没有被用来指导判定是常量还是变量,只是在生成的 harness 中注释了一下
Control-Flow Reconstruction
Winnie 分析从调用函数的返回值到终止条件(例如,retrun 或 exit )的路径的两个API调用之间的控制流。如果找到这样的路径,WINNIE将复制已反编译的控制流代码。
实现中没有这一部分,感觉这一部分的效用也不会太大
Data-Flow Reconstruction
- 返回值的简单流
- (多级)指针指向关系
- 别名:如果将相同的非常量值用作参数两次,则这两次使用被认为是构成单个变量的别名。
Harness Validation and Finalization
- 首先,我们检查 harness 的稳定性。我们对几个正常的输入进行控制;如果 harness 坏了,我们立即丢弃它。
- 其次,我们评估了 harness 探索程序状态的能力。具体地说,我们对 harness 进行短期模糊处理,并检查代码覆盖率是否随着时间的推移而增加。
- 最后,我们测试 harness 的执行速度。在所有稳定、有效的 harness 中,我们向用户提供最快的harness。
实现中没看到这一部分
Implementation
## Collect Dynamic Run Traces & Harness generation
### One trace
pin.exe -t source/tools/Tracer/Release/Tracer.dll ^
-logdir "cor1_1" -trace_mode "all" ^
-only_to_target "test.exe" -only_to_lib "test.dll" ^
-- test.exe input1
python3 synthesizer.py harness -t cor1_1/drltrace.PID.log -d cor1_1/memdump -s START_FUNCTION
### One correct + one incorrect
pin.exe -t source/tools/Tracer/Release/Tracer.dll ^
-logdir "cor1_2" -trace_mode "all" ^
-only_to_target "test.exe" -only_to_lib "test.dll" ^
-- test.exe input1
pin.exe -t source/tools/Tracer/Release/Tracer.dll ^
-logdir "cor2_1" -trace_mode "all" ^
-only_to_target "test.exe" -only_to_lib "test.dll" ^
-- test.exe input2
python3 syn-multi.py harness -t ./ -s START_FUNCTION
## LCA Analysis
pin.exe -t source/tools/Tracer/Release/Tracer.dll ^
-logdir "dom" -trace_mode "dominator" ^
-only_to_target "test.exe" -only_to_lib "test.dll" ^
-- test.exe
python3 dominator.py -s CreateFileW -e CloseHandle -sample "" -t ./dom/drltrace.PID.log -d ./dom/memdump/
代码都在仓库下的 harnessgen 文件夹下,有一份 README 介绍了基本的一些用法,包括基于 one trace 生成 harness、基于 One correct + one incorrect 生成 harness、LCA 分析。还也有些细节没有交代清楚,导致看的时候很困惑:
- 什么叫 One correct + one incorrect?看起来是 multiple trace。
- 既然有基于多 log 的合成方法,为什么要提及基于单 log 的合成方法?
- LCA 分析输出的地址怎么帮助合成 harness?
Tracing by PIN (harnessgen/lib/library_trace.cpp)
首先讲一下动态分析部分,三种用法都会涉及收集 Trace。
在 main 函数中主要注册了两个设置插桩的回调函数:
//FOR MODULE
IMG_AddInstrumentFunction(event_module_load, nullptr);
//FOR BB
TRACE_AddInstrumentFunction(event_app_instruction, nullptr);
- event_module_load:在模块加载的时候记录模块名和基地址。
- event_app_instruction:在函数内分别对 DirectCall、Ret、IndirectCall、IndirectJmp 设置回调函数 at_call、at_ret、at_call_ind 和 at_jmp_ind 用于记录调用情况。
需要注意的是可以以五种模式生成 trace 文件,分别如下:
- ALL:记录目标与模块之间(T2M、M2T)的调用和返回信息(包括数据指针类型参数指向的数据在调用前后的内存 dump),结果用于后续合成 harness
- DOMINATOR:记录所有与文件操作相关的调用(FR),目标内部(T2T)和目标对模块(T2M)的调用信息,结果用于后续 LCA 分析
UNIQUE:print out unique dlls loadedRELATION:print out all dlls related with specified dllINDIRECT:
One trace (synthesizer.py)
One trace 就是运行一次程序,基于单个 Trace 生成 harness,只能把 Trace 搬到 harness 上,并做一些简单的指针分析。对应的流程主要是下面三个函数调用:
if args.action == 'harness':
syn = SingleSynthesizer(args.trace_file, args.dump_dir,
args.functype, args.start_func, args.sample_name)
syn.build_body()
syn.emit_code()
- SingleSynthesizer 的初始化主要是调用到 Trace.build() 来解析 log 文件的内容,主要生成 calltrace[] 和 rettrace[] 列表。此外还会通过 FunctypeManager.get() 函数调用 IDA 运行脚本来获取库中函数约定,即参数类型和个数。
- SingleSynthesizer.build_body() 就是按照 call 的顺序,将其一个一个搬到 harness 中,通过一个核心函数 Synthesizer.ret_arg_code() 来确定函数的具体参数,以及是否需要新定义参数所用变量,在其内部做一些指针分析(pointer analysis)。
- Synthesizer.emit_code() 没有具体语义,将上一步生成的 body 组合到模板中生成最终的 harness。
Synthesizer.ret_arg_code()
-
如果参数类型是 ‘D’ 则代表其不是函数指针和代码指针,直接用其数值常量作为参数
elif args[x][0][1] == 'D': # TODO: consider data-type when unpack raw_value = args[x][0][0] _type = args_type[x].replace("*", "") need_to_define.append("") arguments.append(hex(raw_value)) -
如果参数类型是 ‘CD’ 表示其可能是一个代码指针,只是添加了一行注释表示可能是代码指针,同样当成 ‘D’ 类数据处理。
elif args[x][0][1] == 'CP': # print self.trace.caller_baseasddr raw_value = args[x][0][0] _type = args_type[x].replace("*", "") append_str = " /* Possible code pointer offset: %s */" % hex( int(raw_value) - self.trace.caller_baseaddr) # print append_str # we provide the information about the code pointer need_to_define.append("") arguments.append(hex(raw_value) + append_str) -
‘DP’ 代表是数据指针,处理相对复杂一些,这里我将注释写入到代码中
def ret_arg_code(self, cid, args, args_dump, args_type, args_ptr): """ - cid: call id - args: actual argument values - args_dump: followed result from pointer array[0]=pre, array[1]=post - args_type: inferred type for each argument """ need_to_define = [] arguments = [] pointer_defined_flag = False # 1) will use raw value (basically) # 2) if pointer, we define variable and pass the address # 3) if pointer indicates 0, we allocate heap with 1000 size for x in range(len(args)): pointer_defined_flag = False # data pointer if args[x][0][1] == 'DP': # TODO: consider data-type when unpack # 1) sample_name 调用脚本文件的参数,指定了运行程序获得 Trace 时的输入文件名, # 这里如果字符串能匹配就直接用 fuzzer 生成的 input 文件名作为参数 first_string = next(strings(args_dump[x][0])) if self.sample_name.encode() in first_string: arguments.append("filename") continue else: dumped = hex(u32(args_dump[x][0])) _type = args_type[x].replace("*", "") # 1-1) infer chuck of actual sample is used in the function # TODO # 2) 如果指针指向的数据为 0,则分配一个 0x1000 的内存,并将指针作为参数 # (考虑未初始化内存的情况,但仅仅通过前四个字节是否为 0 来判断,给人的感觉十分局限) if dumped == '0x0': # we always allocate enough space for pointer to zero (could be initialization) need_to_define.append("%s* c%d_a%d = (%s*) calloc (%d, sizeof(%s));" % (_type, cid, x, _type, BINREAD, _type)) arguments.append("&c%d_a%d" % (cid, x)) # 否则指针指向的数据可能有意义,需要定义一个该数值变量(考虑多级指向关系?) else: # Is the address is already referenced from the previous pointer? # 3) 检查该地址所对应的变量是否已经定义,若已经定义则直接重用变量地址作为参数 if args[x][0][0] not in self.defined_pointer: # search_pointer 会找两个地方 # 1] 之前(包括当前)的所有调用的参数中是否有相同的地址 # (如果之前参数也有这个值,就应该会能在 defined_pointer 找到吧?) # 2] 之前(包括当前)的所有调用的参数如果是数据指针,在 post-dump 里搜索该地址, # (如果找到了则说明这个地址是由库函数返回的,很可能也由库函数分配内存) result = self.search_pointer(args[x][0][0], cid, internal_use=True) result_arg = self.check_searched_result(result, "arg") result_dump = self.check_searched_result(result, "dump") # print result_arg # print result_dump # 3-1) 如果由在 post-dump 里找到了该地址则直接对 post-dump 对应 call 的参数内存进行访问 # (这里多半需要人工修复,因为对很多非 0 数据指针并没有初始化足够大小的 buf) if result is not None and result_dump is not None: _cid = result_dump[1] _arg = result_dump[2] _idx = result_dump[3] ptrname = self.ret_pointer_at_dump(_cid, _arg, _idx) self.defined_pointer[args[x][0][0]] = ptrname need_to_define.append('') arguments.append(ptrname) continue # 3-2) what if the address is used by another arguments? elif False: # elif result is not None and result_arg is not None: # print result self.defined_pointer[args[x][0] [0]] = "&c%d_a%d" % (cid, x) need_to_define.append( "%s c%d_a%d = %s;" % (_type, cid, x, dumped)) # 3-3) 直接定义一个变量存储数值,然后返回变量地址 else: self.defined_pointer[args[x][0] [0]] = "&c%d_a%d" % (cid, x) need_to_define.append( "%s c%d_a%d = %s;" % (_type, cid, x, dumped)) pointer_defined_flag = True # if it is pre-defined, we do nothing else: need_to_define.append('') # If we don't have choice, we define new pointer arguments.append(self.defined_pointer[args[x][0][0]]) # 4)检查指针指向的数值是否是另一个指针,即指针指向指针的情况 # e.g., arg1|A --> 0x1000, arg1|B --> A -> 0x1000 # ==> B = &A (not just raw value of A) if pointer_defined_flag == True: # now, we are selecting the referenced value (this is also address) # 搜索指针指向的数值是否作为其他 call 的参数,即只考虑在 arg 中出现 # (逻辑不是很清晰感觉,这里首先并没保证指向的数据是一个地址) # (在我的例子里就会出现 &(0x1c) 这样的问题) __result = self.search_pointer( args[x][1][0], cid, internal_use=True) __result_arg = self.check_searched_result(__result, "arg") if __result_arg is not None: result_cid = __result_arg[1] result_arg = __result_arg[2] # history = {cid: (need_to_define, arguments)} # 找到之前这个数值是怎么被定义的,例如是 c0_a0,就会为当前生成一个 &(c0_a0) previous_argument = self.history[result_cid][1][result_arg] addr_previous_argument = self.ret_addr_of_var( previous_argument) # rollback del self.defined_pointer[args[x][0][0]] arguments = arguments[:-1] need_to_define = need_to_define[:-1] # append arguments self.defined_pointer[args[x][1] [0]] = addr_previous_argument arguments.append(addr_previous_argument) need_to_define.append('') elif args[x][0][1] == 'CP': """ failed trial code_pointer = args[x][0][0] self.defined_pointer[args[x][0][0]] = "&c%d_a%d" % (cid, x) need_to_define.append("%s c%d_a%d = %s;" % (_type, cid, x, code_pointer)) arguments.append(self.defined_pointer[args[x][0][0]]) """ # print self.trace.caller_baseasddr raw_value = args[x][0][0] _type = args_type[x].replace("*", "") append_str = " /* Possible code pointer offset: %s */" % hex( int(raw_value) - self.trace.caller_baseaddr) # print append_str # we provide the information about the code pointer need_to_define.append("") arguments.append(hex(raw_value) + append_str) # 'D' 代表参数既不是代码指针也不是数据指针,直接在参数中使用常量 elif args[x][0][1] == 'D': # TODO: consider data-type when unpack raw_value = args[x][0][0] _type = args_type[x].replace("*", "") need_to_define.append("") arguments.append(hex(raw_value)) return need_to_define, arguments
可以看到首先,代码在实现上考虑的情况并不完备甚至略显粗糙,其次这样生成的 harness 的过程和论文中的过程不匹配,此外我不太理解这一步基于 one trace 生成的 harness 的作用
One correct + one incorrect (syn-multi.py)
运行程序多次生成多个 trace,包括相同的样本多次运行和不同的样本多次运行,可以做一些进一步的比对分析来生成更为优雅的 harness。main 函数比单个的要复杂一些,大致骨架如下:
# 解析 Trace log 文件
syn_cor1 = MultiSynthesizer(cor_trace_1, dumpdir,
functype_pn, args.start_func, args.sample_name)
syn_cor2 = MultiSynthesizer(cor_trace_2, dumpdir2,
functype_pn, args.start_func, args.sample_name)
syn_diff = MultiSynthesizer(diff_trace, dumpdir_diff,
functype_pn, args.start_func, args.sample_name)
# 做 log 的 diff 分析
identifier = Identifier(traces)
report = identifier.report
# 生成代码
syn_cor1.build_body(report)
syn_cor1.emit_code()
MultiSynthesizer 和 SingleSynthesizer 初始化的部分是一样的,都是调用 Synthesizer 的构造函数解析 Trace。
Identifier 比对相同 input 的不同 trace 和不同 input 的不同 trace,生成 report 文件供 build_body() 使用。
# comparison result using same input should have result
self.comp_cor = self.compare_cortrace()
# comparison result using different inputs may not have result (i.e., null dict)
self.comp_diff = self.compare_difftrace()
self.report = self.make_report(self.comp_cor, self.comp_diff)
- compare_cortrace() 对两个相同输入文件的每一对的调用(这里是否假设 API 序列完全相同?)调用 Identifier.analyse_args() 比对参数的数值是否相同,如果是指针则比较其引用的数据是否相同。
- compare_difftrace() 只有在两个不同输入文件 API trace 相同的时候才做比对,比对方法也和 compare_cortrace() 一样。
- make_report() 则是简单的将两个 comp 合并到一起。
build_body() 虽然用到了 report,但是交叉引用可以发现 report 只是在输出时进行注释,并没有像论文中说的那样,用来指导 arg 的类型。代码框架类似,但是多了两个不知道为什么 SingleSynthesizer.build_body() 中没有的功能。
- 使用注释提示了对一个函数的连续调用,即可能是 Loop 调用的情况
- 如果两次调用的 src_addr 相差大于 0x20(阈值),则在输出文件中注释。这个不知道什么用,论文中好像也没怎么提及。
综上,diff 的功能也并没有自动集成到类型分析上,这一步和上一步生成的 harness 除了提供一些 diff 注释之外没有太多区别,和论文中出入还是蛮大的
LCA analysis (dominator.py)
LCA analysis 的动态分析使用 Dominator 模式进行 Trace,执行 python 分析脚本之后会输出下面这样的效果,但是作者并没有对这些含义及用法做额外解释。
[*] Displaying Most Frequent Address (Dominator candidates)
>> Total unique harness functions: 571
>> Total number of function address identified: 565
>> Total number of candidate address(es): 2
[*] Dominator analysis
>> Bad candidate (called multiple times):
>> Good candidate (called only once): 0x42c675, 0x42f3b3
>> Candidate address (sorted by the distance from harness): 0x42c675, 0x42f3b3
main 函数里很简单,只是创建了一个 Dominator 类的实例,所有事情都在构造函数中做了。
class Dominator(object):
def __init__(self, trace_pn, dump_pn, start_func=None, end_func=None, sample_name=None):
self.start_cid, self.end_cid, self.interesting_tid, _ = self.ret_interesting_locations()
self.trace = DominatorTrace(self.trace_pn, self.start_cid,
self.end_cid, self.interesting_tid)
self.defined_variables = []
self.defined_pointer = {} # {address:variable_name}
self.body = []
self.history = {}
self.har_addr = {}
""" ALL functions which used in the harness """
for addr in list(self.trace.all_callers.keys()):
# print hex(addr), self.trace.all_callers[addr]
self.har_addr[addr] = self.trace.all_callers[addr]
self.dominator()
- ret_interesting_locations 中会遍历 log 中记录的调用,统计所有 DC、IC、IJ 和 FR 类型的调用记录的 src_addr(但没有使用该返回值);会根据提供的 start_func 和 end_func 确定 start_cid 和 end_cid。
-
DominatorTrace 是 Trace 的一个子类
class DominatorTrace(Trace): # TODO: parse all traces, now we are tracing specified threadID with starting point def __init__(self, trace_pn, start_cid, end_cid, interesting_tid): super().__init__(trace_pn, DUMPDIR, interesting_tid, start_cid, build=False) ... self.callgraph = nx.DiGraph() self.build() self.func_boundary = self.sanitize_func_boundary() # dict{start:dst} self.generate_digraph() # store to self.callgraph- 在 Trace.build() 中遇到 CALL 和 RET 记录时会分别调用重载后的 parse_call() 和 parse_ret()。parse_call() 中会 1)保存调用的关系到 src_to_dst 和 dst_from_src 两个字典中 2)将所有 cid 大于 start_cid 并且 dst_module 不是系统 dll 的 Trace 通过
self.all_callers[src_addr] = te.src_symbol记录下来(这里有两个实现上的问题,一个是判断系统 dll 时用的是文件名和路径进行比较,不可能成立;二一个是 src_symbol 永远都是 None,暂不明白此处的用意)。parse_ret() 中会按照 call/ret 对来推断函数的边界。 - sanitize_func_boundary() 中舍弃一些没有正确推断的函数边界,例如没有 end_addr、函数大小大于 0x10000。
- generate_digraph() 这里用到了nx.DiGraph 来构建图,该函数往 node_list[] 中添加 func_start 作为节点(因为生成的图是函数的指向关系,函数内的所有调用要整合到一个源),往 callgraph 中添加 func_start->dst_addr 作为边。
- 在 Trace.build() 中遇到 CALL 和 RET 记录时会分别调用重载后的 parse_call() 和 parse_ret()。parse_call() 中会 1)保存调用的关系到 src_to_dst 和 dst_from_src 两个字典中 2)将所有 cid 大于 start_cid 并且 dst_module 不是系统 dll 的 Trace 通过
-
图构建好了,解析来是在 Dominator.dominator() 中作主要的 LCA 分析,代码比较长,直接注释到代码中
def dominator(self): # Calculate dominator using DFS and common address (Lowest common ancestor) # self.trace.node_list 是所有被记录到(函数内部发起调用)的 target 内函数地址 unique_code_size = len(self.trace.node_list) all_nodes = self.trace.callgraph.nodes # 1-1)对每个节点,求能到达这个节点的所有节点集合 out # 1-2)将所有 out 集合求并得到 storage,storage 中节点出现的次数代表了可以到达的节点个数 # 1-3)拥有最高出现次数的被确定为 LCA 候选 print("[*] Processing Directed-graph to find dominator") storage = [] # all_callers 是满足 cid >= start_cid && cid <= end_cid 的 src_addr for harness_addr in tqdm(list(self.trace.all_callers)): harness_addr_start = self.trace.get_func_start(harness_addr, merge_boundary=MERGE_BOUNDARY) out = [] # (为什么要倒序遍历) for i in range(unique_code_size - 1, 0, -1): # print(harness_addr, self.trace.node_list[i]) # 要寻找所有其他函数到该函数的通路,所以需要是其他有效节点 if self.trace.node_list[i] == harness_addr_start or self.trace.node_list[i] == 0: continue # 这两个都是在 generate_digraph() 中同步更新的,按道理不会存在 node_list[i] not in all_nodes 的情况 if self.trace.node_list[i] not in all_nodes: continue # print harness_addr_start, self.trace.node_list[i] # 所有可以由 node_list[i] 走到 harness_addr_start 的路径 for path in nx.all_simple_paths(self.trace.callgraph, source=self.trace.node_list[i], target=harness_addr_start, cutoff=50): out = out + path # before [4371555, 4375480, 4376181, 4371555, 4375480, 4387763, 4376181, 4371555, 4375480] # after [4371555, 4375480, 4376181, 4387763] # 求所有可达 harness_addr 路径中的所有节点 out = list(dict.fromkeys(out)) storage = storage + out print("[*] Displaying Most Frequent Address (Dominator candidates)") # 计算每个节点出现的次数,即计算每个节点可以到达的节点数 func_counter: typing.Dict[int, int] = {} for func_addr in storage: func_counter[func_addr] = func_counter.get(func_addr, 0) + 1 # 排序 popular_words = sorted(func_counter, key=func_counter.get, reverse=True) most_func_count = func_counter[popular_words[0]] # 找到可以到达最多节点的节点(可能有多个,即这里体现了把 LCA 的祖先也考虑的想法) report_addr = [] for addr in func_counter.keys(): if func_counter[addr] == most_func_count: report_addr.append(addr) # 所有 cid >= start_cid && cid <= end_cid 的数量 print(" >> Total unique harness functions: %d" % (len(self.trace.all_callers))) # func_counter 中最高的计数数值(在这里最高的就代表是 LCA 或其祖先) print(" >> Total number of function address identified: %d" % most_func_count) # 拥有最高计数数值的所有地址 print(" >> Total number of candidate address(es): %d" % len(report_addr)) # print(" >> Total number of candidate address(es): %d" % ', '.join(report_addr)) # Heuristics """ 1. display report address with CID (CALLID) 2. display observed number of that address in the trace (less number is desirable, should be 1?) 3. display upper address of that function """ # 2-1)只被调用一次的候选 harness 被认为是 good,其他是 bad print("\n[*] Dominator analysis") candidate = {} candidate["good"] = [] candidate["bad"] = [] for addr in report_addr: count = self.ret_addr_count_trace(addr) # how many times called? if count == 1: candidate["good"].append(addr) else: candidate["bad"].append(addr) # 2-2)根据 distance_from_startcid 对 good 进行排序 final_report = {} for good_addr in candidate["good"]: final_report[good_addr] = self.distance_from_startcid(good_addr) final_report = sorted(final_report, key=final_report.get, reverse=False) print(" >> Bad candidate (called multiple times): %s" % ', '.join(hex(addr) for addr in candidate["bad"])) print(" >> Good candidate (called only once): %s" % ', '.join(hex(addr) for addr in candidate["good"])) print(" >> Candidate address (sorted by the distance from harness): %s" % ', '.join(hex(addr) for addr in final_report))
可以看到 LCA 分析同样也和论文中的方法略有出入,而且这里只输出了 candidate 的地址,因为 target 内部通常没有符号,而 synthesizer 里要求的 start_func 是符号,可能是暂时没有联结使用的原因
Conclusion
运行代码确实能生成出一份 harness 代码,但是从代码的一些注释还有未使用变量等都可以清晰的表明这是一个半成品,同论文中所描述的方法具有相当一部分的差距,同时一些实现上的问题也导致生成的 harness 无法直接使用。本来这篇文章中的一些控制流和数据流依赖确定方法就逊色于同期的一些基于 Trace 的方法,加之实现上的问题,需要改进的地方有很多。