IMF: Inferred Model-based Fuzzer
Introduction
IMF 是SoftSec-KAIST 2017 年发表在 CCS 上的研究成果,同 Winnie 类似的也是基于动态 trace 自动生成 harness 的工具,不过 IMF 的目标是闭源操作系统 API 模型,实现上以 MacOS 为例。
Methodology
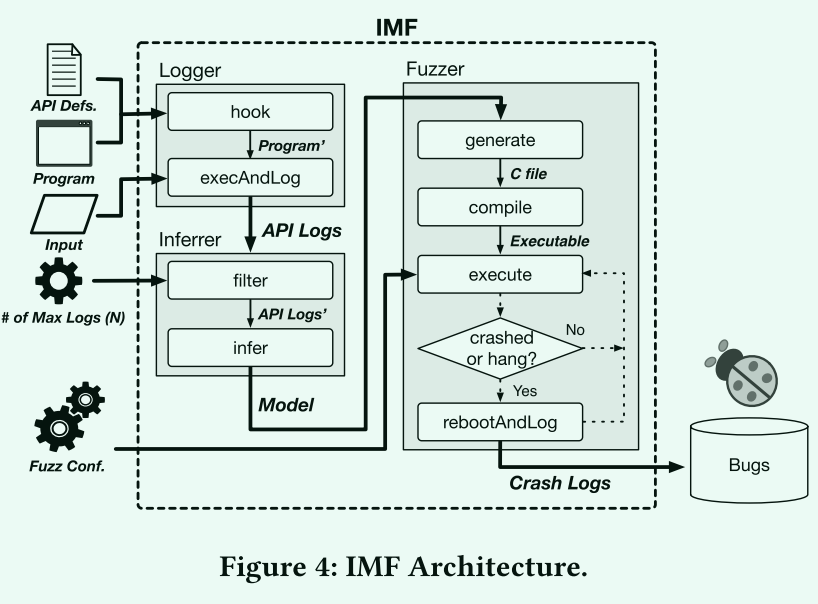
Logger
- 首先,我们需要考虑我们应该从记录器记录多少数据。我们仅存储到一个级别的间接指针(按道理存储更多级别的指针更有助于恢复依赖)当调用挂钩的API调用时,日志记录器检查参数的类型,并决定记录哪些值。
- 数值指针存储指针地址和指向的数值
- 字符串指针存储指针地址和指向的字符串
-
其次,我们应该为GUI应用程序生成输入,以便记录API调用。我们使用 PyUserInput [3] 为正在运行的每个程序构造鼠标和键盘事件。
这一点工具中并未体现,但也不是本文工作重心
Inferrer
- Log Filtering
- inferrer 的过滤功能从给定的整个日志集中选择N(N=2)个具有最长公共前缀的日志。
- 然后,它收集每个选定日志的前缀部分,以便构造一组具有完全相同顺序和相同数量的 API 调用的调用序列 S。
- API Model Inference
- 首先,S 中的调用序列已经显示了API 函数调用之间的顺序依赖性。我们可以通过考虑API 调用的顺序应遵循与 S 中的序列之一完全相同的顺序来过度近似顺序依赖关系。
- 其次,我们需要计算数值的依赖性。
- 首先识别常数参数:在不同的序列中都表现出同样数值
-
接下来,我们考虑从输出参数到输入参数的近似数据流:对于某个系统调用的给定参数数值,我们检查是否有任何具有相同输出值的先验函数调用。当输入参数依赖于多个输出参数时,我们采用最近调用的函数中使用的参数。
上述的方法可能会导致错误的数值依赖,Inferrer 采用两个技术缓解:
- 它排除数据流到一个恒定的输入参数
- 我们得出N个调用序列中每个序列的值依赖性集,并计算它们的交集。
- 最后,对于那些没有任何依赖关系的非恒定输入变量,我们简单地使用日志中出现的相同具体值。由于有N个可能的值可以使用,因此我们随机取其中一个值。
Fuzzer
- Mutation Strategy
- Sequence Replication:迭代更多次系统调用序列
- ParameterMutation:IMF执行基于类型的参数突变。它用对突变函数的调用替换AST中的每个参数。
-
Data Collection
IMF 在发现错误时可能会触发内核恐慌或系统挂起。因此,它必须在执行程序之前将PRNG 种子的当前值保存到永久存储中。(琐碎的细节)
Implementation
gen-hook (src/hook.py)
对应用的 API 调用进行跟踪,使用的是 MacOS 特有的基于 DYLD_INSERT_LIBRARIES 来 Hook 调用的方式(笔者对 MacOS 不熟悉)。好像是在 __DATA 段加上一个表 __interpose 包含原始的函数名和新的函数名,编译生成动态链接库,并在运行程序前使用 DYLD_INSERT_LIBRARIES 指定,就可以拦截对函数的调用。
IMF 依赖于 src/const.py 中手动对所有需要跟踪的 API 编写描述,包括返回类型、函数名、参数名及类型、参数用作输入输出的信息等。hook.py 中会根据 API Defs 来生成一个替换函数,会在调用原函数前记录所调用的函数名,以及所有输入参数的具体数值,并在对原始函数的调用之后记录返回值和所有输出参数的具体数值。
# API Defs
[('kern_return_t', 'IOConnectSetCFProperty'), [('io_connect_t', 'connect', {}), ('CFStringRef', 'propertyName', {}), ('CFTypeRef', 'property', {})]],
[('kern_return_t', 'IOConnectCallMethod'), [('mach_port_t', 'connection', {}), ('uint32_t', 'selector', {}), ('const uint64_t *', 'input', {'cnt': 'inputCnt', 'IO': 'I', 'size': 8}), ('uint32_t', 'inputCnt', {}), ('const void *', 'inputStruct', {'cnt': 'inputStructCnt', 'IO': 'I', 'size': 1}), ('size_t', 'inputStructCnt', {}), ('uint64_t *', 'output', {'cnt': '*outputCnt', 'IO': 'O', 'size': 8}), ('uint32_t *', 'outputCnt', {'cnt': 1, 'IO': 'IO', 'size': 4,}), ('void *', 'outputStruct', {'cnt': '*outputStructCnt', 'IO': 'O', 'size': 1}), ('size_t *', 'outputStructCnt', {'cnt': 1, 'IO': 'IO', 'size': 4,})]],
# fake API wrapper
kern_return_t fake_IOConnectSetCFProperty(io_connect_t connect,CFStringRef propertyName,CFTypeRef property){
FILE *fp = fopen(log_path,"a");
flock(fileno(fp),LOCK_EX);
fprintf(fp,"IN ['IOConnectSetCFProperty',");
if(1) fprintf(fp,"{'name':'connect','value': 0x%x,'size' : 0x%lx,'cnt':0x%x, 'data':[",connect, sizeof(io_connect_t),1);
else fprintf(fp,"{'name':'connect','value': 0x%x, 'size' : 0x%lx,'cnt':'undefined', 'data':[",connect,sizeof(io_connect_t));
fprintf(fp,"]},");
if(1) fprintf(fp,"{'name':'propertyName','value': 'CFSTR(\"%s\")','size' : 0x%lx,'cnt':0x%x, 'data':[",CFStringGetCStringPtr(propertyName,kCFStringEncodingMacRoman), sizeof(CFStringRef),1);
else fprintf(fp,"{'name':'propertyName','value': 'CFSTR(\"%s\")', 'size' : 0x%lx,'cnt':'undefined', 'data':[",CFStringGetCStringPtr(propertyName,kCFStringEncodingMacRoman),sizeof(CFStringRef));
fprintf(fp,"]},");
if(1) fprintf(fp,"{'name':'property','value': 0x%x,'size' : 0x%lx,'cnt':0x%x, 'data':[",property, sizeof(CFTypeRef),1);
else fprintf(fp,"{'name':'property','value': 0x%x, 'size' : 0x%lx,'cnt':'undefined', 'data':[",property,sizeof(CFTypeRef));
fprintf(fp,"],'ori':");
log_CFTypeRef(fp,property);
fprintf(fp,"},");
fprintf(fp,"]\n");
kern_return_t ret = IOConnectSetCFProperty(connect,propertyName,property);
fprintf(fp,"OUT ['IOConnectSetCFProperty',");
if(1) fprintf(fp,"{'name':'ret','value': 0x%x,'size' : 0x%lx,'cnt':0x%x, 'data':[",ret, sizeof(kern_return_t),1);
else fprintf(fp,"{'name':'ret','value': 0x%x, 'size' : 0x%lx,'cnt':'undefined', 'data':[",ret,sizeof(kern_return_t));
fprintf(fp,"]},");
fprintf(fp,"]\n");
fclose(fp);
return ret;
}
# API Log
IN ['IOBSDNameMatching',{'name':'masterPort','value': 0x0, 'size' : 0x4,'cnt':0x1, 'data':[]},{'name':'options','value': 0x0, 'size' : 0x4,'cnt':0x1, 'data':[]},{'name':'bsdName','value': '"disk1"', 'size' : 0x4,'cnt':0x1, 'data':[]},]
OUT ['IOBSDNameMatching',{'name':'ret','value': 0x797c6610, 'size' : 0x4,'cnt':0x1, 'data':[]},]
filter-log (src/filter.py)
这一步主要的工作是将所有的 log 文件根据最长公共前缀筛选至 N 个(sample 中 N=2)只包含公共前缀的 log 文件。
核心逻辑就在 find_best 函数里,通过一个 while 循环挨个对 API log 进行处理。groups 是个二维数组,第一维的个数代表当前迭代产生了多少个前缀,第二维代表每个前缀被哪些 log 文件所共有。
- categorize 用于在增加一个 API,即考虑的前缀长度加一之后对 groups 数组进行更新。算法核心是判断每个 group 内部每个 log 新增的 API 是否相同(get 获得基于 API name 计算的 hash 值),将不同的再拆分成为不同的 group。
- pick_best 判断是否完成 filter 的逻辑是:当某次迭代之后,最后一个被超过 N 个 log 文件所共有的前缀也被拆成了几个都不超过 N 的集合,那这个前缀就是被”最多” N 个 log 文件所共有的最长公共前缀,则在所有拥有这个前缀的 log 文件中选 N 个文件作为结果。
def categorize(groups, idx):
ret = []
for group in groups:
tmp = {}
for fn, hvals in group:
hval = get(hvals, idx)
if hval not in tmp:
tmp[hval] = []
tmp[hval].append((fn, hvals))
for hval in tmp:
if hval != None :
ret.append(tmp[hval])
return ret
def pick_best(groups, n):
for group in groups:
if len(group) >= n:
return group[:n]
return None
def find_best(groups, n):
before = None
idx = 0
while len(groups) != 0:
before = groups
groups = categorize(groups, idx)
if pick_best(groups, n) == None:
return pick_best(before, n), idx
idx += 1
utils.error('find_best error')
gen-fuzz (src/model.py)
genfuzz 分为两步,首先 Model 的初始化会对 filtered-log 进行解析生成 AST 并进行数据依赖分析,然后调用 fuzz() 将 AST 输出到代码之中。
def make_model(self, fnames, limit, path, core):
apisets = utils.multiproc(self.load_apilog_multi(limit), fnames, core)
model = Model(apisets)
with open(path, 'wb') as f:
code = model.fuzz(const.CODE_HEAD, const.CODE_TAIL)
f.write(code)
Model 中的数据依赖分析主要就包含两个,常量分析 check_const 和数据流分析。
class Model:
def __init__(self, apisets):
self.mapis = []
for idx in range(len(apisets[0])):
apilog = apisets[0][idx]
self.mapis.append(Mapi(apilog, idx))
self.check_const(apisets)
self.add_dataflow(apisets)
- check_const 的逻辑很简单,就是看在不同 log 之中,对于同一个 API 调用的某个参数的数值是否发生变化。
-
add_dataflow 也不复杂
before 数组存储了所有已经遍历过的 API 的返回数值以及输出数据信息,每次遍历一个 API 就会调用 update_before 更新 before 数组。
def update_before(before, apilog, mapi, n): # 获得输出数据指针参数 dic = apilog.get('ol') # 获得返回数值 if not apilog.is_void(): dic[const.RVAL] = apilog.get('rval_log') for name, arglog in dic.iteritems(): value = arglog.get_log('value') key = value add_before(before, key, mapi, n, (name,VALUE,0)) if arglog.is_ptr() and value !=0: # 如果数组指针,则把数组中的每一个数组都更新到 before 中 data = arglog.get_log('data') for idx in range(len(data)): add_before(before, data[idx], mapi, n, (name,DATA,idx)) #key = apilog,n ; pos = arg,DATA,n def add_before(before, value, mapi, n, pos): key = mapi,n if not value in before: before[value] = {} if not key in before[value]: before[value][key] = {} before[value][key][pos] = True Class Model: def add_dataflow(self, apisets): for apiset in apisets: before = {} for idx in range(len(apiset)): apilog = apiset[idx] mapi =self.mapis[idx] mapi.add_dataflow(before, apilog) update_before(before, apilog, mapi, idx)add_dataflow 最终会进到 get_df 或 get_inter_df 中。如果是对第一个 log 进行分析,则进入 get_df,按照 value 在 before 数组中查找所有的依赖关系(因为之后会对不同 log 文件的依赖取交集所以这里需要所有的关系)。如果是在已经分析过一次依赖关系之后,就会进入到 get_inter_df,会对两个 dataflow 取交集。
def get_df(before, value): ret = {} if value in before: # 如果这个数值在之前的返回数据中出现过,则把所有的位置都作为依赖返回 df = before[value] for key1 in df: ret[key1] = {} for key2 in df[key1]: ret[key1][key2] = df[key1][key2] return ret def get_inter_df(before, value, df): ret = {} if value in before: for key1 in df: if key1 in before[value]: # 必须得是 df(dataflow_other) 里出现过,取交集 for key2 in df[key1]: if key2 in before[value][key1]: if not key1 in ret : ret[key1] = {} ret[key1][key2] = True return ret Class Mapi: def add_dataflow(self, before, apilog) ilog = apilog.get('il') # self.il 代表输入参数的 log for name in self.il: self.il[name].add_dataflow(before, ilog[name]) Class Marg: def add_dataflow(self, before, arglog): # 如果是数组,则对于每个数组的数值进行一次分析 if self.is_array(): cnt = arglog.get_log('cnt') assert(cnt == len(self.data)) values = arglog.get_log('data') for i in range(cnt): self.data[i].add_dataflow(before, values[i]) value = arglog.get_log('value') self.value.add_dataflow(before, value) class Mval: def add_dataflow(self, before, value): self.raw.append(value) if self.is_const() == False: # 不对常数做数据流分析 if self.dataflow == None: self.dataflow = get_df(before,value) else: # 说明不是第一个 log 文件,两个 dataflow 取交集 self.dataflow = get_inter_df(before,value,self.dataflow)
每个 API 都有一个自己的序号,最后生成的 fuzz 的时候在依赖关系中找到 API idx 和对应的变量名拼起来就可以引用了。
mach_port_t masterPort_0 = (mach_port_t) mut_int(0);
uint32_t options_0 = (uint32_t) mut_int(0);
char * bsdName_0 = (char *) mut_ptr("disk1");
CFMutableDictionaryRef ret_0 = IOBSDNameMatching(masterPort_0, options_0, bsdName_0);
mach_port_t masterPort_1 = (mach_port_t) mut_int(0);
CFDictionaryRef matching_1 = (CFDictionaryRef) mut_ptr(ret_0);
Conclusion
毕竟是比较久远的文章,从方法上来讲比较简略。
- 最长公共前缀的方法感觉比较脆弱,没有强有力的证据说明 API 模型不会间插使用。
- 数据依赖的分析基于直接的数值分析也很不精准。
- API 描述依赖于昂贵的人工成本,可扩展性不强。
- 对参数的变异也没有考虑嵌套的结构化信息,对 API 顺序方面不提供变异策略。
- …