[paper reading] Design and Implementation of Nested Virtualization
Introduction
目前的主流 CPU 虽然提供了虚拟化支持,大幅提高了虚拟机的执行速度,但是其在设计上并没有考虑嵌套虚拟化的问题。IBM 维护了一个叫做 Turtles 的项目,基于 KVM 实现了嵌套虚拟化解决方案,目前已经被并入 KVM 的 mainstream 了。
本篇论文描述了早期的一些嵌套虚拟化解决方案,发表在 USENIX 2010 上。
Methodology
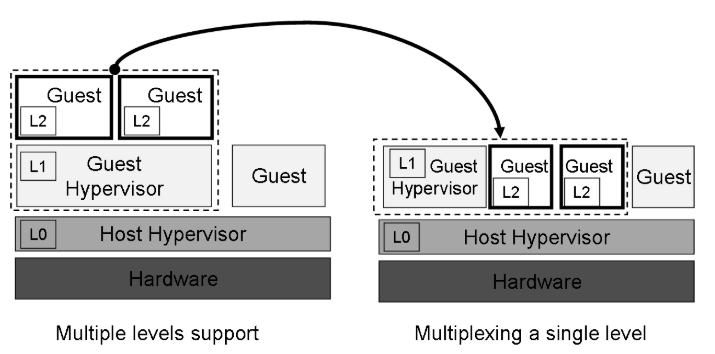
嵌套虚拟化有两种可能的模型,它们在底层架构提供的支持量上有所不同。
- 在第一个模型中,嵌套虚拟化的多级架构支持,每个管理程序处理由直接在其上运行的任何客户管理程序的敏感指令引起的所有陷阱。(IBM System z)
- 第二种模型,嵌套虚拟化的单级架构支持,只有单一的 hypervisor 模式,任何嵌套级别的陷阱都由这个 hypervisor 处理。无论发生陷阱的级别如何,执行都会返回到级别 0 的陷阱处理程序。(Intel VMX & AMD SVM)

从根本上说,我们的嵌套虚拟化方法通过在单一级别的虚拟化架构支持上多路复用多个虚拟化级别(多个虚拟机管理程序)来工作。
- 当 L1 希望运行虚拟机时,它会通过标准架构机制启动它。这会导致陷阱,因为 L1 没有在最高权限级别运行(与 L0 一样)。为了运行虚拟机,L1 提供了要启动的虚拟机的规范,其中包括其初始指令指针和页表根等属性。该规范必须由 L0 转换为可用于直接在裸机上运行 L2 的规范,例如,通过将内存地址从 L1 的物理地址空间转换为 L0 的物理地址空间。因此,L0 复用了 L1 和 L2 之间的硬件,两者最终都作为 L0 虚拟机运行。
- 当任何管理程序或虚拟机导致陷阱时,将调用 L0 陷阱处理程序。然后陷阱处理程序检查陷阱指令及其上下文,并决定该陷阱是否应该由 L0 处理(例如,因为陷阱上下文是 L1)还是是否将其转发给负责的管理程序(例如,因为陷阱发生在L2 应由 L1 处理)。在后一种情况下,L0 将陷阱转发给 L1 进行处理。
-1] CPU: Nested VMX Virtualization
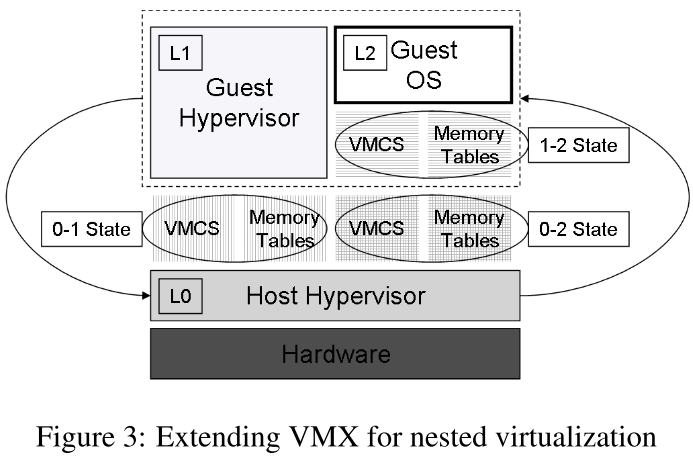
以 root 模式 (L0) 运行的管理程序以访客模式运行其他管理程序 (L1)。 L1 虚拟机管理程序有他们在根模式下运行的错觉。他们的虚拟机 (L2) 也以访客模式运行。如图 3 所示,L0 负责复用 L1 和 L2 之间的硬件。 CPU 使用 VMCS0→1 环境规范运行 L1。 VMCS0→2分别用于运行L2。这两个环境规范都由 L0 维护。此外,L1 在其自己的虚拟化环境中创建 VMCS1→2。尽管 VMCS1→2 从未加载到处理器中,但 L0 使用它为 L1 模拟启用了 VMX 的 CPU。
-
VMX Trap and Emulate
L1 执行的大多数 VMX 指令首先导致从 L1 到 L0 的 VMExit,然后是从 L0 到 L1 的 VMEntry。对于用于运行新 VM 的指令 vmresume 和 vmlaunch,过程是不同的,因为 L0 需要模拟从 L1 到 L2 的 VMEntry。因此,L1 对这些指令的任何执行首先会导致从 L1 到 L0 的 VMExit,然后是从 L0 到 L2 的 VMEntry。
-
VMCS Shadowing
为简洁起见,我们省略了有关特定 VMCS 字段如何合并的一些细节。有关完整的详细信息,鼓励有兴趣的读者参考 KVM 源代码。
L0 必须考虑 VMCS1→2 中定义的所有规范以及 VMCS0→1 中定义的规范来创建 VMCS0→2。 VMCS0→2 中定义的主机状态必须包含 CPU 正确从 L2 切换回 L0 所需的值。此外,VMCS1→2 主机状态必须复制到 VMCS0→1 来宾状态。
-
VMEntry and VMExit Emulation
当导致 L2 VMExit 的事件仅与 L0 相关时,L0 处理该事件并恢复 L2(类比非嵌套场景,硬件层面发生事件,CPU透明处理,hypervisor继续运行);由与 L1 相关的事件引起的 VMExit,L0 通过将处理器更新的 VMCS0→2 字段复制到 VMCS1→2 并恢复 L1,将事件转发给 L1。
-2] MMU: Multi-dimensional Paging
当前的硬件仅支持一维或两个维度(级别)的转换,而不是嵌套虚拟化所需的三个。我们将介绍一种新技术,多维分页,用于将三个所需的转换表复用到硬件中可用的两个转换表上。
-
传统的一种叫做影子页表的虚拟化 MMU 方案(SPT - Shadow page table):
访客创建访客页表,将访客虚拟地址转换为访客物理地址。基于此表,管理程序创建一个新的页表,即影子页表,它将客户虚拟地址直接转换为相应的主机物理地址。然后管理程序使用这个影子页表而不是客户的页表来运行客户。管理程序必须捕获所有客户分页更改,包括页面错误异常、INVLPG 指令、上下文切换(导致使用不同的页表)和所有客户对页表的更新。
-
为了提高虚拟化性能,x86 架构最近添加了二维页表用于虚拟化,通常称为 HAP(Hardware assisted paging):
在转换客户虚拟地址时,处理器首先使用常规客户页表将其转换为客户物理地址。然后,它使用第二个表,英特尔称为 EPT(AMD 称为 NPT),将客户物理地址转换为主机物理地址。当 EPT 表中缺少条目时,处理器会生成 EPT 违规异常。管理程序负责维护 EPT 表及其缓存(可以使用 INVEPT 刷新),并负责处理 EPT 违规,而访客页面错误可以完全由访客处理。
几种常见的 MMU 虚拟化方案介绍可见:虚拟机之内存虚拟化(MMU Virtualization)
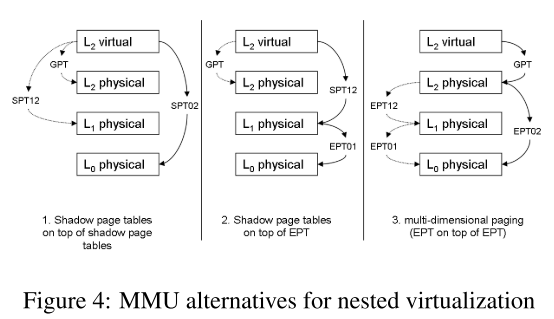
相应地就可以衍生出上图所示的几种嵌套虚拟化 MMU 的方案:
- Shadow-on-shadow
- Shadow-on-EPT
-
EPT-on-EPT(本文方法)
我们展示了与 shadow-on-EPT 相比,使用多维页表的一些有用工作负载的速度提高了三倍以上。
在多维页表中,与在二维页表中一样,每个级别都创建自己单独的转换表。对于 L1 创建 EPT 表,L0 向 L1 公开 EPT 功能,即使硬件仅提供单个 EPT 表。由于硬件中只有一个 EPT 表可用,因此应该将两个 EPT 表压缩为一个。
为了保持 EPT0→2 的正确性,L0 管理程序需要知道 L1 对 EPT1→2 所做的任何更改。 L0 将 EPT1→2 的内存区域设置为只读,从而在 L1 尝试更新它时造成陷阱。 L0 将根据 EPT1→2 中更改的条目更新 EPT0→2。 L0 还需要捕获所有 L1 INVEPT 指令,并相应地使 EPT 缓存无效。
为了进一步提高性能,L0 还允许 L1 使用 VPID。使用此功能,CPU 用数字虚拟处理器 ID 标记 TLB 中的每个转换,从而无需在每个 VMEntry 和 VMExit 上刷新 TLB。由于每个管理程序都可以随意选择这些 VPID,它们可能会发生冲突,因此 L0 需要将 L1 使用的 VPID 映射到有效的 L0 VPID。
VPID 是类似 PCID 一样来减少 TLB 刷新的机制,可以参考 Intel 手册或 TLB 的那些事
-3] I/O: Multi-level Device Assignment
这一块译者了解的不多
通常有三种方法可以为来宾虚拟机提供 I/O 服务。
- 虚拟机管理程序模拟已知设备并且客户使用未修改的驱动程序与其交互
- 在客户中安装半虚拟驱动程序
- 主机分配一个真实设备给虚机然后直接控制设备
设备分配通常提供最佳性能,因为它最大限度地减少了虚拟机与其管理程序之间与 I/O 相关的世界切换的数量,虽然它使实时迁移复杂化,但设备分配和实时迁移可以和平地进行共存。
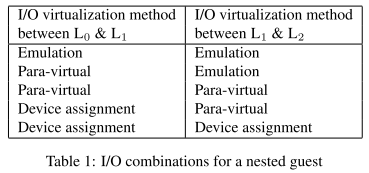
单层客户机的这三种基本 I/O 方法在两层嵌套客户机情况下暗示了九种可能的组合。在九个潜在组合中,我们评估了更有趣的一些案例。我们将在下面描述最后一个选项,我们称之为多级设备分配。多级设备分配允许 L2 来宾直接访问设备,绕过两个管理程序。这种直接设备访问需要处理 DMA、中断、MMIO 和 PIO。
虚拟化环境中的设备 DMA 很复杂,因为客户驱动程序使用客户物理地址,而设备中的内存访问是通过主机物理地址完成的。 DMA 问题的常见解决方案是 IOMMU,这是一个位于设备和主存储器之间的硬件组件。它使用管理程序准备的转换表将客户物理地址转换为主机物理地址。然而,目前可用的 IOMMU 仅支持单级地址转换。同样,我们需要将两层转换表压缩到硬件中可用的一层。
- 这可以使用半虚拟 IOMMU 来完成:L1 中设置 IOMMU 上从 L2 到 L1 地址的映射的代码被对 L0 的超级调用替换。 L0 将该映射中的 L1 地址更改为相应的 L0 地址,并将生成的映射(从 L2 到 L0 地址)放入 IOMMU。
- 一种更好的方法是让 L0 模拟 L1 的 IOMMU,它可以运行未修改的客户机。 L1 认为它运行在带有 IOMMU 的机器上,并在其上设置了从 L2 到 L1 地址的映射。 L0 拦截这些映射,将 L1 地址重新映射到 L0 地址,并在真实 IOMMU 上构建 L2-to-L0 映射。
-*] Micro Optimizations
嵌套虚拟机管理程序的客户在两个主要地方比在裸机虚拟机管理程序上运行的同一客户慢。
- 首先,L1 和 L2 之间的转换比 L0 和 L1 之间的转换慢。
- 其次,在 L1 管理程序中运行的退出处理代码比在 L0 中运行的相同代码慢。
-
Optimizing transitions between L1 and L2
根据 Intel 的规范,对 VMCS 区域的读取或写入必须使用 vmread 和 vmwrite 指令执行,它们在单个字段上运行。我们凭经验注意到,在某些情况下,可以直接访问 VMCS 数据而不会产生不良副作用,绕过 vmread 和 vmwrite 并使用大内存副本一次复制多个字段。
-
Optimizing exit handling in L1
管理程序中的退出处理代码在 L1 中运行时比在 L0 中运行的相同代码要慢。这种减速的主要原因是退出处理代码中的特权指令导致的额外退出。在英特尔 VMX 中,虚拟机管理程序使用特权指令 vmread 和 vmwrite 来读取和修改来宾和主机规范。
相比之下,在 AMD SVM 中,可以使用普通的内存加载和存储直接读取或写入来宾和主机规范。该模型的明显优势是 L0 不会干预,而 L1 会修改 L2 规范。消除捕获和模拟特殊指令的需要减少了退出次数并提高了嵌套虚拟化性能。
为了避免在每个 vmread 和 vmwrite 上陷入陷阱,L0 可以做的一件事是在 L1 指令流中对有问题的 vmread 和 vmwrite 指令进行二进制翻译,方法是在第一次调用此类指令时进行陷阱,然后将其重写为分支到不会被捕获的内存加载或存储。