Technical background of MoonShine
Build tips
- Golang 在包管理机制上有过变革,详见 GO111MODULE。遵循 README 中的 build 步骤,需要首先设置环境变量 GO111MODULE=off。
Strace
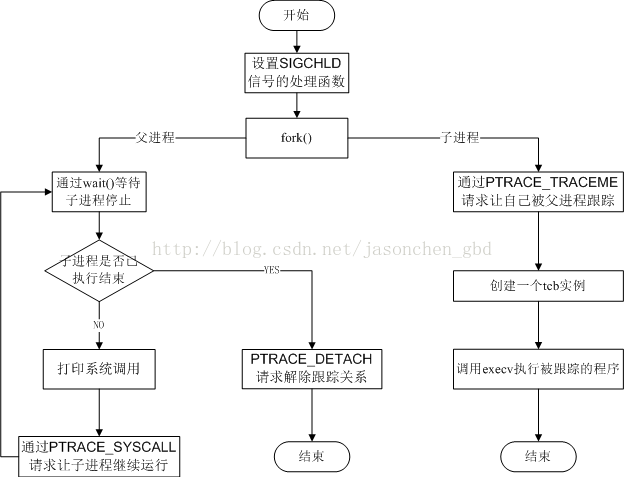
strace 通常用来跟踪应用的系统调用和信号,基于 ptrace 实现,简化后的框架如下图所示
- strace 先 fork() 子进程,执行要运行的命令
- 然后执行系统调用
ptrace(PTRACE_ATTACH, childPid)或ptrace(PTRACE_TRACEME, childPid)即可跟踪子进程。 - 循环调用
ptrace(PTRACE_SYSCALL, ..)跟踪被 attach 的进程, kernel 会返回当前的系统调用 number,然后处理下输出结果。
strace 源码框架很庞大,主体结构在 strace.c 里,简化后的框架同上图一致,这里笔者没有去探究代码的其他部分。
// strace.c
static void ATTRIBUTE_NOINLINE ATTRIBUTE_NORETURN
exec_or_die(void)
{
struct exec_params *params = ¶ms_for_tracee;
if (params->fd_to_close >= 0)
close(params->fd_to_close);
if (!daemonized_tracer && !use_seize) {
if (ptrace(PTRACE_TRACEME, 0L, 0L, 0L) < 0) { // <--- PTRACE_TRACEME
perror_msg_and_die("ptrace(PTRACE_TRACEME, ...)");
}
}
execv(params->pathname, params->argv);
}
static void
startup_child(char **argv)
{
...
pid = fork(); // <--- fork()
if (pid < 0) {
perror_msg_and_die("fork");
}
if ((pid != 0 && daemonized_tracer)
|| (pid == 0 && !daemonized_tracer)
) {
exec_or_die();
}
...
}
static bool
trace(void)
{
// call trace_syscall_exiting() & trace_syscall_entering()
if (trace_syscall(tcp, &sig) < 0) {
return true;
}
goto restart_tracee;
restart_tracee:
if (ptrace_restart(PTRACE_SYSCALL, tcp, sig) < 0) {
/* Note: ptrace_restart emitted error message */
exit_code = 1;
return false;
}
return true;
}
int
main(int argc, char *argv[])
{
init(argc, argv); // -> call startup_child()
exit_code = !nprocs;
while (trace())
;
...
}
How does strace work 一文中有简要介绍在内核中 ptrace 相关的一些实现原理,里面讲解基于内核版本 v3.13,经过检查 v5.18 相关代码并没有太大改动。
-
PTRACE_ATTACH 代码流程
static int ptrace_attach(struct task_struct *task, long request, unsigned long addr, unsigned long flags) { bool seize = (request == PTRACE_SEIZE); int retval; retval = -EIO; if (seize) { // PTRACE_SEIZE 的参数检查 ... } else { flags = PT_PTRACED; } audit_ptrace(task); retval = -EPERM; // tracee 不能是内核线程 if (unlikely(task->flags & PF_KTHREAD)) goto out; // 不能和当前线程在同一进程 if (same_thread_group(task, current)) goto out; retval = -ERESTARTNOINTR; if (mutex_lock_interruptible(&task->signal->cred_guard_mutex)) goto out; task_lock(task); // 检查当前进程是否有权利 trace 目标 retval = __ptrace_may_access(task, PTRACE_MODE_ATTACH_REALCREDS); task_unlock(task); if (retval) goto unlock_creds; write_lock_irq(&tasklist_lock); retval = -EPERM; // tracee 不能已经结束了 if (unlikely(task->exit_state)) goto unlock_tasklist; // tracee 不能已经被 trace 了 if (task->ptrace) goto unlock_tasklist; // 设置 PTRACED flag task->ptrace = flags; ptrace_link(task, current); if (!seize) // ATTACH 会停止 tracee 而 SEIZE 不会 send_sig_info(SIGSTOP, SEND_SIG_PRIV, task); spin_lock(&task->sighand->siglock); if (task_is_stopped(task) && task_set_jobctl_pending(task, JOBCTL_TRAP_STOP | JOBCTL_TRAPPING)) signal_wake_up_state(task, __TASK_STOPPED); spin_unlock(&task->sighand->siglock); retval = 0; unlock_tasklist: write_unlock_irq(&tasklist_lock); unlock_creds: mutex_unlock(&task->signal->cred_guard_mutex); out: if (!retval) { wait_on_bit(&task->jobctl, JOBCTL_TRAPPING_BIT, TASK_KILLABLE); proc_ptrace_connector(task, PTRACE_ATTACH); } return retval; } SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr, unsigned long, data) { ... if (request == PTRACE_ATTACH || request == PTRACE_SEIZE) { ret = ptrace_attach(child, request, addr, data); if (!ret) arch_ptrace_attach(child); goto out_put_task_struct; } ... } -
PTRACE_SYSCALL 代码流程
会一路经由 sys_ptrace->arch_ptrace->ptrace_request->ptrace_resume 到 ptrace_resume 里进行处理,最终设置 syscall_work 上的标志。
#define set_task_syscall_work(t, fl) \ set_bit(SYSCALL_WORK_BIT_##fl, &task_thread_info(t)->syscall_work) static int ptrace_resume(struct task_struct *child, long request, unsigned long data) { bool need_siglock; if (!valid_signal(data)) return -EIO; if (request == PTRACE_SYSCALL) // 设置标志 set_task_syscall_work(child, SYSCALL_TRACE); else clear_task_syscall_work(child, SYSCALL_TRACE); ... // 唤醒线程 wake_up_state(child, __TASK_TRACED); if (need_siglock) spin_unlock_irq(&child->sighand->siglock); return 0; } -
syscall 回调
这一部分有少许改动,首先entry_64.S 代码位置现在位于 arch/x86/entry 目录下,其次现在系统调用表的调用链发生了变化,调用具体 syscall 函数在 arch/x86/entry/common.c 中 entry_SYSCALL_64->do_syscall_64->do_syscall_x64->sys_call_tableunr。
而回调函数在 do_syscall_64 中分叉,调用链为 entry_SYSCALL_64->do_syscall_64->syscall_enter_from_user_mode->__syscall_enter_from_user_work。
再经过一系列调用最后会进入 ptrace_report_syscall 给 tracee 发送一个 SIGTRAP,这个信号可以被 tracer 捕获到,然后 tracer 就可以读取各种需要的数据。
static __always_inline long __syscall_enter_from_user_work(struct pt_regs *regs, long syscall) { unsigned long work = READ_ONCE(current_thread_info()->syscall_work); if (work & SYSCALL_WORK_ENTER) syscall = syscall_trace_enter(regs, syscall, work); return syscall; } static long syscall_trace_enter(struct pt_regs *regs, long syscall, unsigned long work) { long ret = 0; .. // SYSCALL_WORK_SYSCALL_TRACE 即 set_task_syscall_work(child, SYSCALL_TRACE) 设置的 bit if (work & (SYSCALL_WORK_SYSCALL_TRACE | SYSCALL_WORK_SYSCALL_EMU)) { ret = arch_syscall_enter_tracehook(regs); if (ret || (work & SYSCALL_WORK_SYSCALL_EMU)) return -1L; } ... syscall_enter_audit(regs, syscall); return ret ? : syscall; } static inline __must_check int arch_syscall_enter_tracehook(struct pt_regs *regs) { return tracehook_report_syscall_entry(regs); } static inline __must_check int tracehook_report_syscall_entry( struct pt_regs *regs) { return ptrace_report_syscall(PTRACE_EVENTMSG_SYSCALL_ENTRY); } static inline int ptrace_report_syscall(unsigned long message) { int ptrace = current->ptrace; if (!(ptrace & PT_PTRACED)) return 0; current->ptrace_message = message; ptrace_notify(SIGTRAP | ((ptrace & PT_TRACESYSGOOD) ? 0x80 : 0)); /* * this isn't the same as continuing with a signal, but it will do * for normal use. strace only continues with a signal if the * stopping signal is not SIGTRAP. -brl */ if (current->exit_code) { send_sig(current->exit_code, current, 1); current->exit_code = 0; } current->ptrace_message = 0; return fatal_signal_pending(current); }退出时的代码流程同理
Kcov
kcov 以适合覆盖率引导的模糊测试(随机测试)的形式公开内核代码覆盖率信息。正在运行的内核的覆盖率数据通过 “kcov” 调试文件导出。覆盖收集是基于任务启用的,因此它可以捕获单个系统调用的精确覆盖。
请注意,kcov 并非旨在收集尽可能多的覆盖范围。它旨在收集或多或少的稳定覆盖,这是系统调用输入的函数。为了实现这个目标,它不会收集软/硬中断的覆盖范围,并且禁用内核的一些固有的非确定性部分(例如调度程序、锁定)的检测。
kcov 还能够从检测代码中收集比较操作数(此功能当前需要使用 clang 编译内核)。
启用 kcov
- 配置内核需要开启 CONFIG_KCOV=y
- 如果需要收集比较操作数,设置 CONFIG_KCOV_ENABLE_COMPARISONS=y
- 只有在挂载了 debugfs 后,才能访问分析数据
mount -t debugfs none /sys/kernel/debug
收集代码覆盖率信息的用法在官方给出的样例中已经描述得很清楚了
#include <stdio.h>
#include <stddef.h>
#include <stdint.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <unistd.h>
#include <fcntl.h>
#include <linux/types.h>
#define KCOV_INIT_TRACE _IOR('c', 1, unsigned long)
#define KCOV_ENABLE _IO('c', 100)
#define KCOV_DISABLE _IO('c', 101)
#define COVER_SIZE (64<<10)
#define KCOV_TRACE_PC 0
#define KCOV_TRACE_CMP 1
int main(int argc, char **argv)
{
int fd;
unsigned long *cover, n, i;
/*
* kcov 基于 task 可以为单个线程生成准确的覆盖信息
*/
fd = open("/sys/kernel/debug/kcov", O_RDWR);
if (fd == -1)
perror("open"), exit(1);
/* 初始化设置 COVER_SIZE */
if (ioctl(fd, KCOV_INIT_TRACE, COVER_SIZE))
perror("ioctl"), exit(1);
/* mmap 一块内存在内核和用户态之间共享 */
cover = (unsigned long*)mmap(NULL, COVER_SIZE * sizeof(unsigned long),
PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if ((void*)cover == MAP_FAILED)
perror("mmap"), exit(1);
/* 为当前线程开启追踪 */
if (ioctl(fd, KCOV_ENABLE, KCOV_TRACE_PC))
perror("ioctl"), exit(1);
/* buf 的一个数据应该指示了当前 buf 的长度,清零让内核从头开始填充 */
__atomic_store_n(&cover[0], 0, __ATOMIC_RELAXED);
/* That's the target syscal call. */
read(-1, NULL, 0);
/* 读 buf 长度,然后从 buf 中读数据,可以看出数据是地址信息 */
n = __atomic_load_n(&cover[0], __ATOMIC_RELAXED);
for (i = 0; i < n; i++)
printf("0x%lx\n", cover[i + 1]);
/* 取消当前线程的追踪 After this call
* coverage can be enabled for a different thread.
*/
if (ioctl(fd, KCOV_DISABLE, 0))
perror("ioctl"), exit(1);
/* Free resources. */
if (munmap(cover, COVER_SIZE * sizeof(unsigned long)))
perror("munmap"), exit(1);
if (close(fd))
perror("close"), exit(1);
return 0;
}
得到的数据也可以使用 addr2line 来获得对应源码的函数和行覆盖信息
- 如果一个程序需要从多个线程(独立地)收集覆盖率,它需要在每个线程中分别打开 /sys/kernel/debug/kcov。
- 该接口是细粒度的,以允许有效地分叉测试过程。也就是说,父进程打开 /sys/kernel/debug/kcov,启用跟踪模式,mmaps 覆盖缓冲区,然后在循环中分叉子进程。子进程只需要启用覆盖(禁用在线程结束时自动发生)。
kcov 还可以支持收集 cmpcov 信息,用法和收集代码覆盖率信息大体一致,只是单个数据包的结构发生了变化
n = __atomic_load_n(&cover[0], __ATOMIC_RELAXED);
for (i = 0; i < n; i++) {
uint64_t ip;
type = cover[i * KCOV_WORDS_PER_CMP + 1];
/* arg1 and arg2 - operands of the comparison. */
arg1 = cover[i * KCOV_WORDS_PER_CMP + 2];
arg2 = cover[i * KCOV_WORDS_PER_CMP + 3];
/* ip - caller address. */
ip = cover[i * KCOV_WORDS_PER_CMP + 4];
/* size of the operands. */
size = 1 << ((type & KCOV_CMP_MASK) >> 1);
/* is_const - true if either operand is a compile-time constant.*/
is_const = type & KCOV_CMP_CONST;
printf("ip: 0x%lx type: 0x%lx, arg1: 0x%lx, arg2: 0x%lx, "
"size: %lu, %s\n",
ip, type, arg1, arg2, size,
is_const ? "const" : "non-const");
}
两种覆盖收集模式是互斥的(为什么不做到两个 kcov 文件)
暂时没看到 kcov 源码分析比较好的文章,暂时也没有这方面需求,占个坑以后看到了来填