MoonShine: Optimizing OS Fuzzer Seed Selection with Trace Distillation
Introduction
MoonShine 是发表在 USENIX Security 2018 的研究成果。
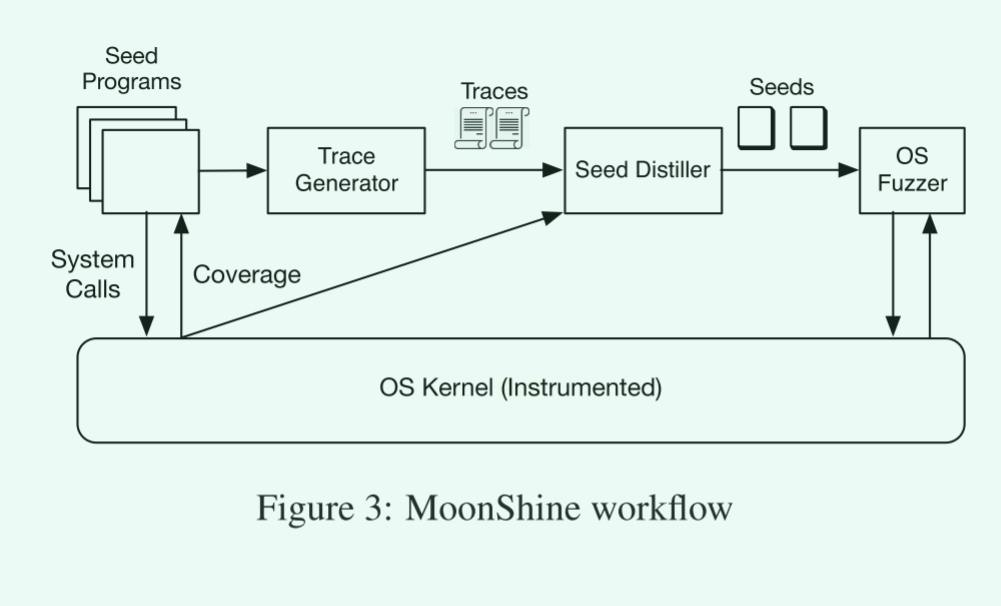
我们在本文中的目标是设计和实现一种在保持相应依赖关系的同时自动提取真实现有程序的跟踪系统调用的技术。在本文中,我们重点从跟踪中提取少量系统调用,同时保持它们的依赖性,并保留完整跟踪实现的大部分覆盖。
Methodology
我们在下面定义了两种不同类型的依赖关系:
- Explicit Dependencies(显式依赖):如果某个系统调用参数依赖于某个系统调用的返回值。
- Implicit Dependencies(隐式依赖):如果某些系统调用的共享参数影响互相的执行。
Distillation Algorithm

- MoonShine从程序跟踪中收集的系统调用列表开始,按覆盖范围从大到小(第8行)对系统调用进行排序。
- 对于列表中的每个调用,如果增加覆盖率则直接舍弃(第10行),否则 MoonShine 都会捕获显式依赖项(第11行)和隐式依赖项(第12行)。
- 这些依赖项以及系统调用被合并(第14行),以便它们在提取的跟踪中的顺序与它们在原始跟踪中的顺序相匹配。
- 这组经过提炼的调用被添加到我们的种子集合中(第16行),用于操作系统模糊化。
Explicit Dependencies

- 对于每个跟踪,MoonShine构建一个依赖关系图,该图由两种类型的节点组成:结果和参数。结果节点对应于系统调用返回的值。结果节点存储以下信息:1) 返回的值,2) 返回类型(指针、int 或语义),3) 生成结果的跟踪中的调用。
- MoonShine 在解析跟踪时构建图形。对于每个调用的返回值,它构造相应的结果节点并将其添加到图中。然后,它将结果节点放置在使用 (type, value) 的组合键索引的结果映射中。
- 对于调用中的每个参数,MoonShine 将检查结果缓存中是否有条目。命中表示存在至少一个系统调用,其结果与当前参数具有相同的类型和值。MoonShine 对存储在映射中的特定类型和值的所有结果节点进行迭代,并将参数节点的一个边添加到图形中的每个结果节点。
- MoonShine 通过枚举调用的参数列表来标识给定调用的显式依赖关系,并且对于每个参数,MoonShine 访问依赖关系图中的相应参数节点。对于从参数节点到结果节点的每个边缘,MoonShine 将生成结果节点的调用标记为显式依赖关系。
这样捕获显式依赖关系的方法有三个例外:
- 系统调用参数本身可能会返回结果,例如管道。为了跟踪这一点,MoonShine 需要一个模板的帮助,该模板标识给定的系统调用,该参数的值由内核设置。有了这样一个模板,MoonShine 还将把参数中返回的值存储在其结果缓存中。
- 其次,像 mmap 这样的内存分配调用会返回一系列值。系统调用可能取决于范围内的值,但不取决于显式返回的值。MoonShine 通过专门跟踪 mmap 或 SystemV 调用的内存分配来处理这个问题。在解析跟踪时,它会生成一个活动映射列表。如果指针参数的值在活动映射内,MoonShine 会将参数的边添加到生成该映射的调用中。
- 最后一个例外是,放在单独的蒸馏程序中的两个种子,被发现相互依赖。在这种情况下,MoonShine将两个程序合并为一个。
Implicit Dependencies

如果 c_a 的写依赖项(如果 c 向 v 写入,则全局变量 v 是系统调用 c 的写依赖项)和c_b 的读依赖项(如果 c 在条件语句中读取 v,则全局变量 v 是系统调用 c 的读取依赖项)的交集非空,则调用 c_a 是 cb_ 的隐式依赖项。
这种方法可能会高估或低估给定调用的隐式依赖项的数量:
- 它可能会高估,因为全局变量是读取依赖项的条件可能只适用于特定值。
- 如果变量有别名,而在条件变量中使用别名变量,这种方法可能会低估依赖关系。
Implementation
相关的技术背景部分详见 HERE
strace (strace_kcov.patch)
作者在 strace 的基础上进行了修改,以获得需要的 trace 信息,除了一些可能是有利于 trace log 格式的细小更改,主要是增加获得每个 API 执行覆盖率信息的功能。大体和文档中 kcov 的用法一致,对多进程的情况有更细致的处理。
- 当检测到新的 pid 时创建一个新的结构体,因为每个进程需要不同的 kcov_buf,除了最开始的进程可以直接读取 buf 之外,其他进程的 buf 都必须通过 ptrace 来读取
-
在 setup_kcov.c 中,为一个新的进程初始化 buf 的过程是通过类似 inline hook 的方式实现的,直接通过 ptrace 改写 code 和 regs 让目标进程执行初始化的指令,从执行结果的寄存器中读取出 mmap 出的 kcov_buf 地址
有意思的点在于最新的 kcov 官方文档中说 “a parent process opens /sys/kernel/debug/kcov, enables trace mode, mmaps coverage buffer and then forks child processes in a loop. Child processes only need to enable coverage” 是否意味着内核做了一部分这个操作,并且将新的 buf 区域映射到了原地址?
implicit-dependencies
隐式依赖流的提取使用 Smatch 静态分析工具进行提取,但在仓库中并未发现相关代码,只有一份已经提取好的依赖关系。
- MoonShine 通过注册一个条件挂钩来跟踪读取依赖关系,该挂钩检查条件表达式或其任何子表达式是否包含结构取消引用。在匹配时,钩子会通知 MoonShine 哪个结构和字段是读取依赖项以及 MoonShine 记录的行和函数名称。
- MoonShine 通过注册一元运算符挂钩和赋值挂钩来跟踪写依赖关系。每当一元赋值操作应用于结构遵从性时,一元运算符挂钩就会通知 MoonShine。通知描述了相应的结构名称和字段,MoonShine 将该结构和字段记录为写依赖项。
scanner
scanner 是基于 goyacc 实现的,将 strace 的 log 记录解析为内存中表示。笔者对这部分不熟悉,这部分也不是文章重点,遂略过。(这一步按照 pid 将不同进程的 API 序列分离)
- scanner/lex.rl 是词法分析器
- scanner/strace.y 是语法分析器
parser
parser 有两个作用,一个是将 im-memory 表示转换为 syzkaller 的 prog 形式,二是做显示依赖信息的提取。
是由于工具想要和 syzkaller 结合,输出 syzkaller 可以使用的 corpus,所以这部分实现上交织着 syzkaller 的 type 和 strace 的type 比较难懂,而且和论文中的描述也有出入
对于每个进程的 API 序列(一个 log 可能有多个进程的序列)都调用 ParseProg 进行解析,遍历序列中的每一个 call 调用 parseCall 完成具体的解析过程。
func parseCall(ctx *Context) (*prog.Call, error) {
// 根据 CallName 在 syzkaller 中寻找模板
straceCall := ctx.CurrentStraceCall
syzCallDef := ctx.Target.SyscallMap[straceCall.CallName]
retCall := new(prog.Call)
retCall.Meta = syzCallDef
ctx.CurrentSyzCall = retCall
// 有一些函数模板需要进一步处理,例如 bpf$BPF_PROG_WITH_BTFID_LOAD
// 需要进一步解析参数等信息来生成对应 syzkaller 类型
Preprocess(ctx)
if ctx.CurrentSyzCall.Meta == nil {
//A call like fcntl may have variants like fcntl$get_flag
//but no generic fcntl system call in Syzkaller
return nil, nil
}
retCall.Ret = strace_types.ReturnArg(ctx.CurrentSyzCall.Meta.Ret)
// 跟踪内存分配相关 API,特殊处理,捕获其依赖关系
if call := ParseMemoryCall(ctx); call != nil {
return call, nil
}
for i := range retCall.Meta.Args {
var strArg strace_types.Type = nil
if i < len(straceCall.Args) {
strArg = straceCall.Args[i]
}
// 解析每个参数到 syzkaller 的类型,并捕获返回流的显式依赖
if arg, err := parseArgs(retCall.Meta.Args[i], strArg, ctx); err != nil {
Failf("Failed to parse arg: %s\n", err.Error())
} else {
retCall.Args = append(retCall.Args, arg)
}
//arg := syzCall.Args[i]
}
// 解析返回参数,更新返回流的依赖关系
parseResult(retCall.Meta.Ret, straceCall.Ret, ctx)
return retCall, nil
}
parser 主要解析两类直接依赖关系
-
VMA 依赖关系
在 ParseMemoryCall 中根据 memory API 的名字分发到不同的处理函数,例如在 ParseMmap 里面会调用 ctx.State.Tracker.CreateMapping() 来创建一个映射维护当前内存调用影响的地址范围 (Tracker 用来维护 vma 映射)。
func ParseMmap(mmap *prog.Syscall, syscall *strace_types.Syscall, ctx *Context) *prog.Call { call := &prog.Call{ Meta: mmap, Ret: strace_types.ReturnArg(mmap.Ret), } ctx.CurrentSyzCall = call length := uint64(0) length = ParseLength(syscall.Args[1], ctx) length = (length/pageSize + 1) * pageSize addrArg, start := ParseAddr(length, mmap.Args[0], syscall.Args[0], ctx) ... ctx.State.Tracker.CreateMapping(call, len(ctx.Prog.Calls), call.Args[0], start, start+length) //All mmaps have fixed mappings in syzkaller return call }对于 mprotect 系统调用,由于其需要使用一个由 mmap 返回的区域地址,所以应该是依赖于 mmap 调用,在 ParseMprotect 中就有调用 AddDependency 来添加这份依赖关系,AddDependency 会去 Tracker 里查找地址落入了哪个 maping,然后在 ctx.DependsOn 中记录下依赖关系。
func AddDependency(start, length uint64, addr prog.Arg, ctx *Context) { if mapping := ctx.State.Tracker.FindLatestOverlappingVMA(start); mapping != nil { dependsOn := make(map[*prog.Call]int, 0) dependsOn[mapping.GetCall()] = mapping.GetCallIdx() for _, dep := range mapping.GetUsedBy() { dependsOn[ctx.Prog.Calls[dep.Callidx]] = dep.Callidx } ctx.DependsOn[ctx.CurrentSyzCall] = dependsOn dep := tracker.NewMemDependency(len(ctx.Prog.Calls), addr, start, start+length) mapping.AddDependency(dep) } } func ParseMprotect(mprotect *prog.Syscall, syscall *strace_types.Syscall, ctx *Context) *prog.Call { call := &prog.Call{ Meta: mprotect, Ret: strace_types.ReturnArg(mprotect.Ret), } ctx.CurrentSyzCall = call addrArg, address := ParseAddr(pageSize, mprotect.Args[0], syscall.Args[0], ctx) length := ParseLength(syscall.Args[1], ctx) lengthArg := prog.MakeConstArg(mprotect.Args[1], length) protArg := ParseFlags(mprotect.Args[2], syscall.Args[2], ctx, false) AddDependency(address, length, addrArg, ctx) // < --- here call.Args = []prog.Arg{ addrArg, lengthArg, protArg, } return call }SYSTEM V shm call 也在这里处理,原文说 shm 分为两步,第一步 shmget 设置大小,第二步 shmat 得到地址。但实现上只处理了 shmat 没有处理 shmget,导致 shmat 时对 CreateMapping 调用参数 size 是用的固定值
-
返回值依赖关系
首先在处理返回值时,如果返回值的类型为 ResourceType(syzkaller 模板里定义的),就记录到缓存 ctx.Cache 中
func parseResult(syzType prog.Type, straceRet int64, ctx *Context) { if straceRet > 0 { //TODO: This is a hack NEED to refacto lexer to parser return values into strace types straceExpr := strace_types.NewExpression(strace_types.NewIntsType([]int64{straceRet})) switch syzType.(type) { case *prog.ResourceType: ctx.Cache.Cache(syzType, straceExpr, ctx.CurrentSyzCall.Ret) } } }然后在 parseArgs 遇到 resource_type 的参数时调用 Parse_ResourceType,去 Cache 里面查找是对应 resource 类型是否有相同的值,从而建立依赖关系。
func Parse_ResourceType(syzType *prog.ResourceType, straceType strace_types.Type, ctx *Context) (prog.Arg, error) { if syzType.Dir() == prog.DirOut { res := strace_types.ResultArg(syzType, nil, syzType.Default()) ctx.Cache.Cache(syzType, straceType, res) return res, nil } switch a := straceType.(type) { case *strace_types.Expression: val := a.Eval(ctx.Target) if arg := ctx.Cache.Get(syzType, straceType); arg != nil { res := strace_types.ResultArg(arg.Type(), arg.(*prog.ResultArg), arg.Type().Default()) return res, nil } res := strace_types.ResultArg(syzType, nil, val) return res, nil case *strace_types.Field: return Parse_ResourceType(syzType, a.Val, ctx) default: panic("Resource Type only supports Expression") } }
distill
func (d *ImplicitDistiller) Distill(progs []*prog.Prog) (distilled []*prog.Prog) {
seeds := d.Seeds
fmt.Printf("Performing implicit distillation with %d calls contributing coverage\n", len(seeds))
// 通过 seeds.cover 的长度进行排序
sort.Sort(sort.Reverse(seeds)) // sort seeds by inidividual coverage.
heavyHitters := make(Seeds, 0)
var target *prog.Target = nil
for _, prog := range progs {
if target == nil {
target = prog.Target
}
// 利用 parser 的直接依赖结果来生成 UpstreamDependencyGraph 和 DownstreamDependents
d.TrackDependencies(prog)
}
// 过滤掉不能增加覆盖率的种子
heavyHitters = d.getHeavyHitters(seeds)
//heavyHitters = seeds
for _, seed := range heavyHitters {
// 对每个 seed 获得其对应 call 及其所有依赖的 calls 得到最后的 distilledProg
d.AddToDistilledProg(seed)
}
distilledProgs := make(map[*prog.Prog]bool)
for _, seed := range seeds {
if _, ok := d.CallToDistilledProg[seed.Call]; ok {
distilledProgs[d.CallToDistilledProg[seed.Call]] = true
}
}
fmt.Printf("Total Distilled Progs: %d\n", len(distilledProgs))
...
return
}
Discussion
- 虽然 MoonShine 没有自己编写 API 模板,但是其 API 参数类型信息依赖于 strace 中的 API 模板参数信息(scanner),和 syzkaller 中的参数类型信息(parser)
- Resource 类型是 syzkaller 里用来判断数据显式依赖的类型,在 paser 解析显式依赖的时候直接借用了 Resource 是不是有点奇怪
- …
- 缺少线程之间的依赖跟踪
- 静态分析产生误报